3.2. Equações diferenciais de primeira ordem
A forma geral das EDO de primeira ordem é
A função chama-se variável dependente e é a variável independente. Uma solução da EDO, num intervalo [, ], é qualquer função de que verifica a equação.
Existem em geral muitas soluções, por exemplo, a Figura 3.1 mostra 7 possíveis soluções da equação . Em cada ponto de cada uma das curvas, o declive tem o mesmo valor obtido substituindo as coordenadas do ponto na expressão . As diferentes soluções não se cruzam nunca, porque em cada ponto existe apenas um valor e cada ponto pertence unicamente a uma das soluções da equação diferencial.
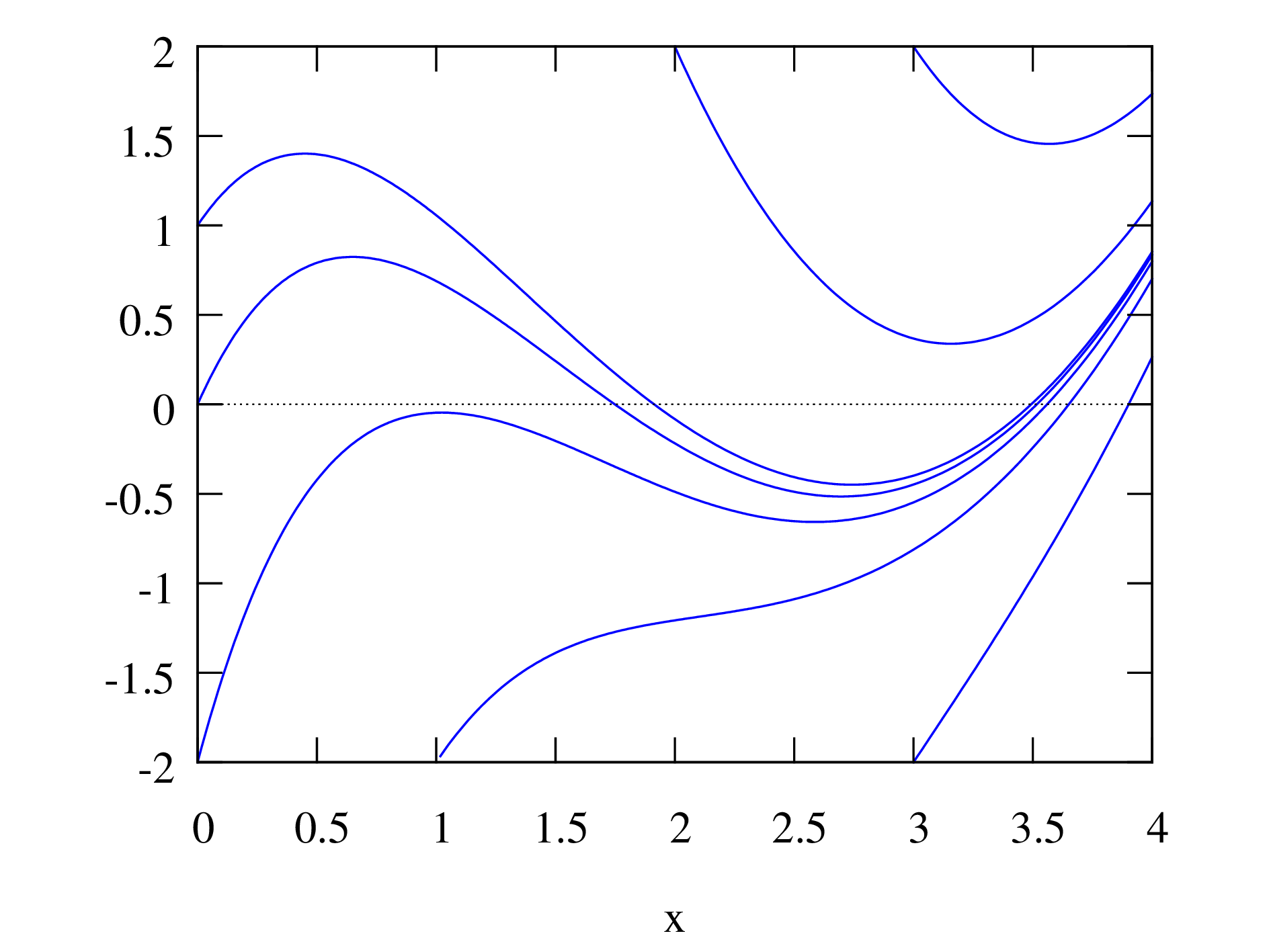
Se for dado um valor inicial para a função no ponto inicial , existe uma única solução , que é a curva tal que e com declive igual a em qualquer valor de .
Os métodos de resolução numérica consistem em calcular o valor da variável dependente numa sequência discreta de pontos {, , , …, }, usando alguma aproximação. O resultado obtido aplicando um determinado método será o conjunto de pontos {(, ), (, ), …, (, )}, que aproximam o gráfico da função . Nos métodos que usam incrementos constantes, o intervalo [, ] divide-se em subintervalos de comprimento , de forma que cada valor na sequência {} é igual ao valor anterior mais :
Por exemplo, a Figura 3.2 mostra a solução da equação diferencial com e condição inicial , no intervalo . Os cinco pontos sobre a curva são a aproximação da função usando apenas 5 pontos com abcissas 0, 1, 2, 3 e 4.
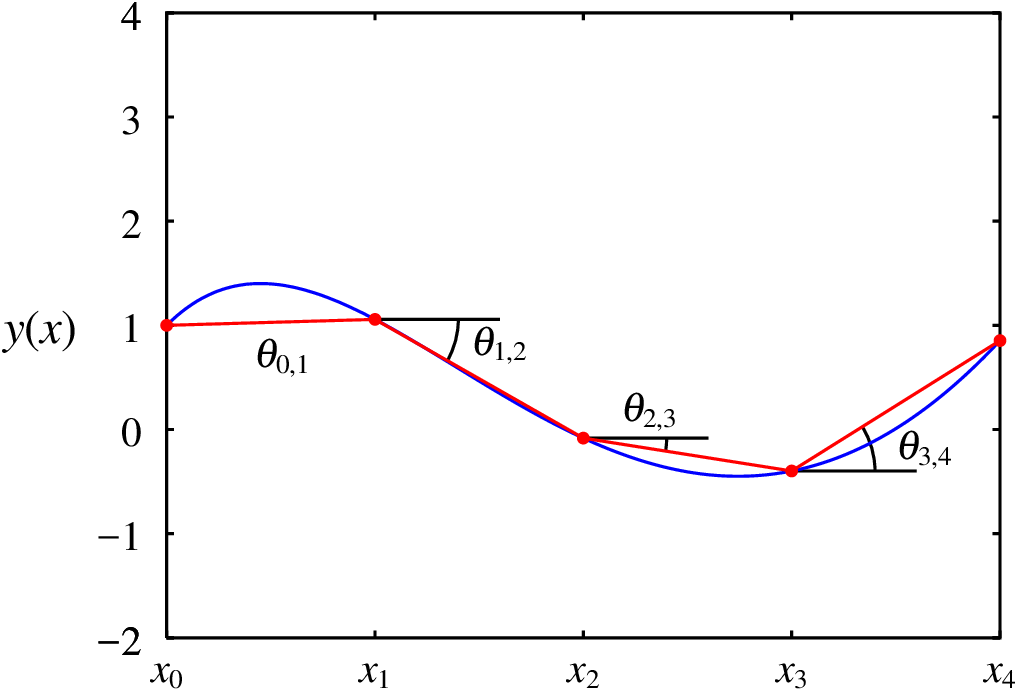
Cada ângulo na figura é a inclinação segmento entre os pontos (, ) e (, ). A tangente do ângulo (declive médio) é igual ao valor médio de no intervalo [, ]. A partir das coordenadas (, ) de um dos pontos, o declive médio permite calcular as coordenadas do ponto seguinte:
Usando estas relações de recorrência de forma iterativa, consegue-se obter as coordenadas de todos os pontos (, ), começando com os valores iniciais dados (, ).
Se os declives médios pudessem ser calculados de forma exata, os resultados obtidos seriam exatos. No entanto, para calcular o valor médio de num intervalo seria necessário conhecer a função , mas quando se usam métodos numéricos é porque não existem métodos para encontrar a expressão analítica dessa função. Os diferentes métodos numéricos que existem para resolver equações diferenciais correspondem a diferentes esquemas para estimar o valor médio aproximado da função em cada intervalo.
3.2.1. Método de Euler
No método de Euler admite-se que ≈ . Ou seja, o valor médio de em cada intervalo é aproximado pelo valor de no ponto inicial do intervalo. Realizando os cálculos no Maxima para o caso considerado acima, em que e com condição inicial = 1, pode usar-se uma lista para armazenar as coordenadas dos pontos; inicia-se a lista com o ponto inicial e define-se a função dada:
(%i1) p: [[0, 1]]$
(%i2) f(x,y) := (x-1)*(x-3)-y$
Os quatro pontos seguintes na sequência são acrescentados à lista , usando um ciclo e as relações de recorrência (3.12) com :
(%i3) for i thru 4 do (
[xi,yi]: last(p),
p: endcons ([xi + 1, yi + f(xi, yi)], p))$
(%i4) p;
(%o4) [[0, 1], [1, 3], [2, 0], [3, −1], [4, 0]]
O gráfico na Figura 3.3 mostra o resultado obtido (segmentos de reta e pontos), comparando-o com a solução exata (curva contínua). Observa-se que a solução obtida com o método de Euler não é uma aproximação muito boa. No entanto, reduzindo o valor dos incrementos em de para um valor menor, deverá ser possível obter uma aproximação melhor. É conveniente reduzir gradualmente o valor de e comparar as soluções com as obtidas com valores maiores de ; se a solução obtida não variar significativamente quando é reduzido, essa solução deverá ser uma boa aproximação da solução verdadeira.
A carga armazenada num condensador ligado a uma pilha e a uma resistência é uma função que depende do tempo e verifica a seguinte equação diferencial
No instante inicial, , a carga no condensador é nula. Usando o método de Euler, encontre uma sequência que aproxime no intervalo .
Resolução. Neste caso, a função que define a derivada não depende da variável independente . Os valores iniciais e a função que define a derivada são:
(%i5) p: [[0, 0]]$
(%i6) f(Q) := 1.25 - Q$
Começando com incrementos de tempo , são necessárias 60 iterações para terminar em .
(%i7) for i thru 60 do (
[t0, Q0]: last(p),
p: endcons ([t0 + 0.1, Q0 + 0.1*f(Q0)], p) )$
O último ponto na lista é:
(%i8) last(p);
(%o8) [5.999999999999995, 1.247753737125107]
Convém repetir o processo, com um valor menor de , por exemplo 0.01 e comparar o novo resultado com o resultado anterior:
(%i9) q: [[0,0]]$
(%i10) for i thru 600 do (
[t0,Q0]: last(q),
q: endcons ([t0 + 0.01, Q0 + 0.01*f(Q0)], q)
)$
(%i11) last(q);
(%o11) [5.9999999999999165, 1.246993738385861]
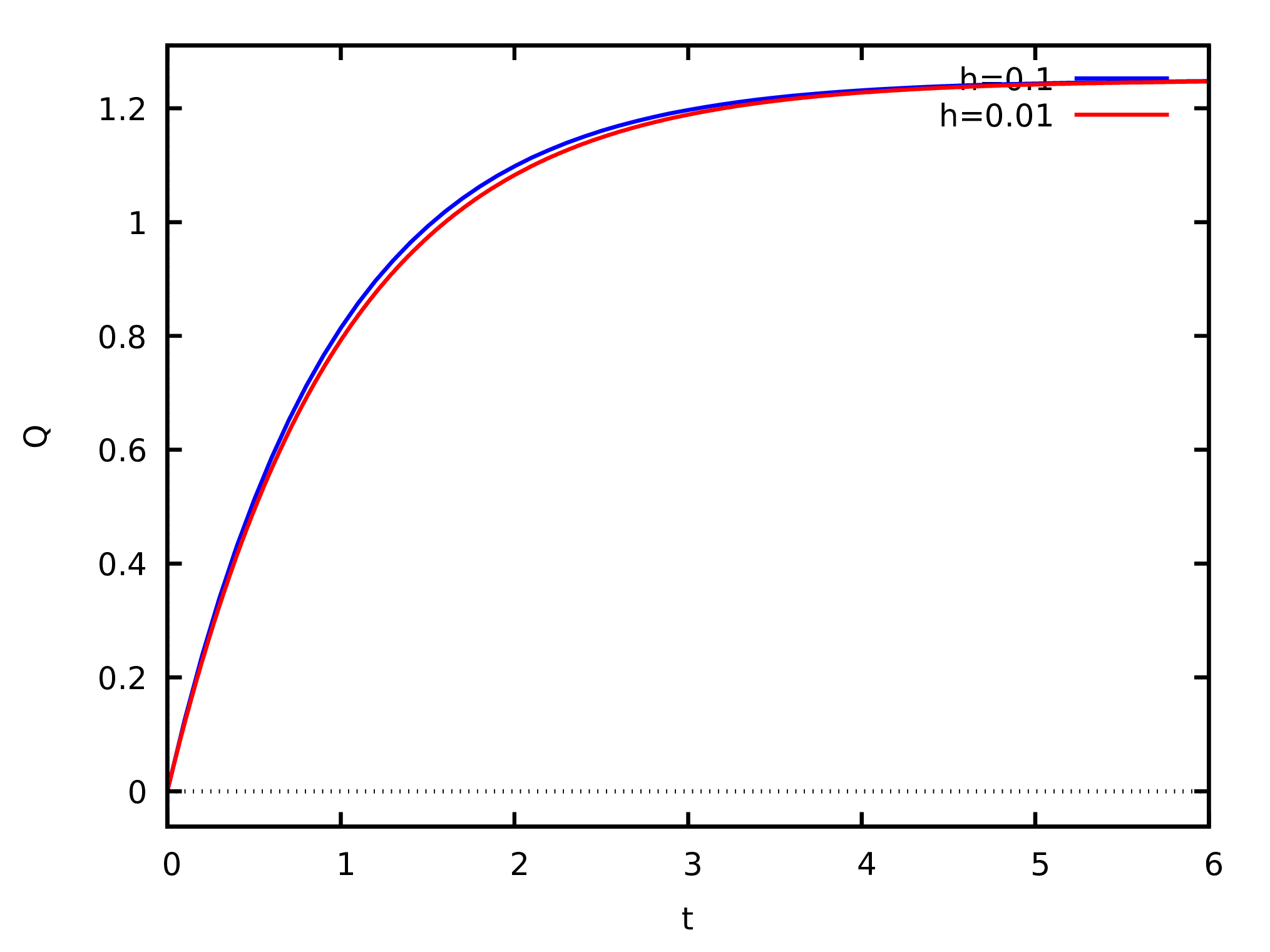
A pesar de que o resultado final coincide em 4 algarismos significativos nos dois casos, é interessante comparar as duas sequências completas. As duas soluções obtidas com e estão armazenadas nas listas e e podem ser representadas num gráfico. A Figura 3.4 mostra que, a pesar de os resultados obtidos para = 6 serem quase idênticos nos dois casos, há uma discrepância entre as duas soluções obtidas, mais visível no intervalo . No entanto, como essa discrepância não é muito grande, espera-se que a solução com já esteja bastante próxima da solução verdadeira. O gráfico foi feito com o seguinte comando
(%i12) plot2d ([[discrete, p], [discrete, q]], [xlabel, "t"], [ylabel, "Q"],
[legend, "h=0.1", "h=0.01"])$
3.2.2. Método de Euler melhorado
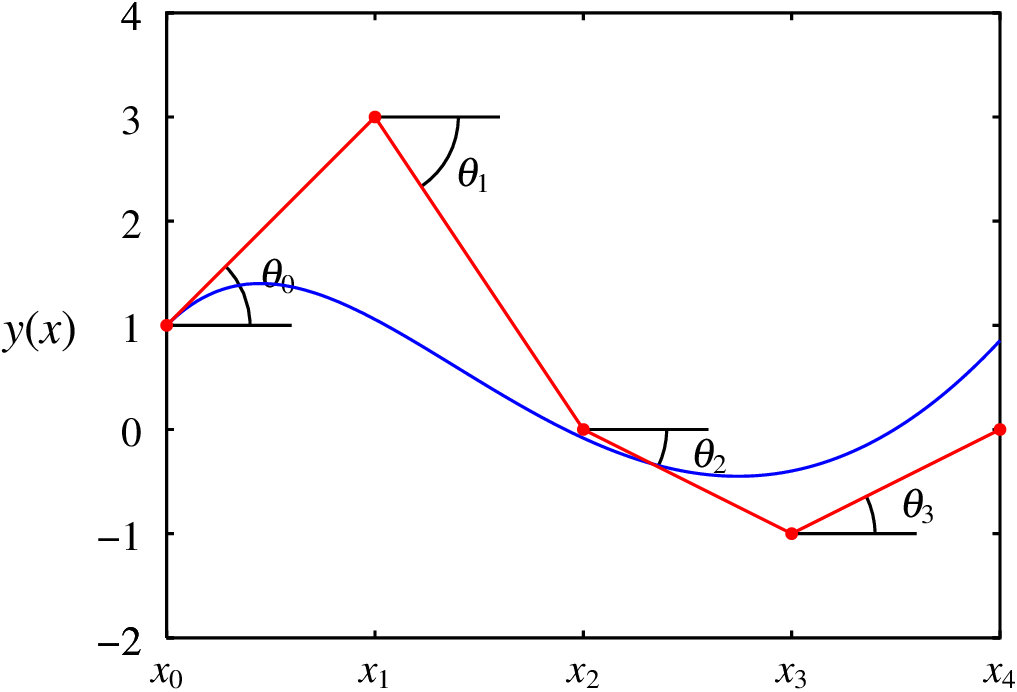
A maior discrepância entre a sequência de pontos que aproximam a solução exata na figura 3.2 e a sequência obtida usando o método de Euler, apresentada na figura 3.3, é no segundo ponto, (, ). O valor médio do declive no primeiro intervalo, que era aproximadamente igual a zero, no método de Euler foi substituído por 2, que é o declive no ponto inicial (, ). A figura 3.2 mostra que, a pesar de que os dois primeiros valores da função, e , são iguais, o declive muda de um valor positivo em para um valor negativo em . No método de Euler usou-se o declive em como valor médio o valor do declive nesse intervalo. Se o valor médio do declive fosse aproximado pela média entre os dois declives em e , o resultado seria muito melhor.
O método de Euler melhorado consiste em admitir que o declive médio é igual à média entre os declives no ponto inicial (, ) e no ponto final (, ); ou seja,
O problema com esta equação é que para poder-se calcular seria necessário saber o valor de , mas esse valor é desconhecido enquanto a solução da equação não for conhecida. É possível fazer uma estimativa inicial do valor que poderá ter e a seguir melhorar essa estimativa. Uma primeira estimativa muito rudimentar consiste em dizer que é igual a .
Com essa abordagem, a resolução da mesma equação considerada na secção anterior, com valor inicial e com 5 pontos no intervalo , pode ser feita assim: começa-se por iniciar a lista de pontos e definir a função que calcula o declive
(%i13) p: [[0,,1]]$
(%i14) f(x,y) := (x-1)*(x-3)-y$
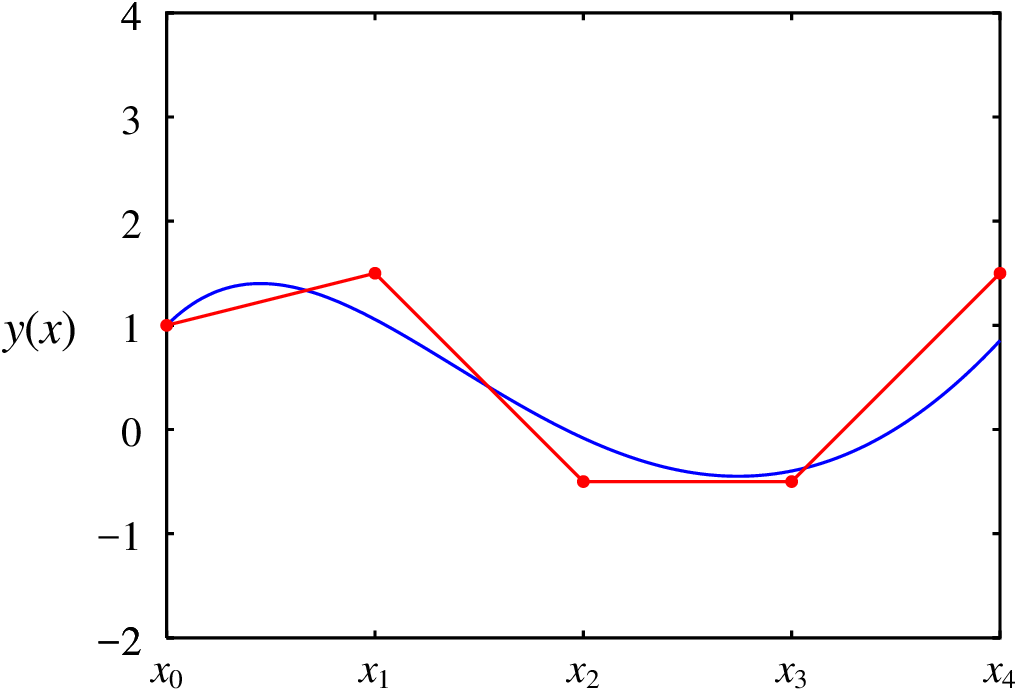
Foi necessário definir novamente a função , já que a definição usada na secção anterior foi logo substituída pela função do exemplo 3.1. Basta repetir as 4 iterações mas usando agora a expressão 3.13 nas relações de recorrência 3.12
(%i15) for i thru 4 do (
[xi,yi]: last(p),
p: endcons ([xi+1, yi + (f (xi, yi) + f (xi+1, yi))/2], p)
)$
(%i16) float (p);
(%o16) [[0.0, 1.0], [1.0, 1.5], [2.0, -0.5], [3.0, -0.5], [4.0, 1.5]]
A figura 3.5 mostra a sequência de pontos obtida, juntamente com a solução exata (curva contínua na figura). O resultado é muito melhor que o resultado obtido com o método de Euler.
O resultado obtido com (%i15) pode ser melhorado se a estimativa inicial for melhorada com o resultado obtido a partir dessa primeira estimativa. Se designarmos à primeira estimativa do valor de , então , como foi usado em (%i15). A segunda estimativa é: . Esse valor estará mais próximo do valor real de do que a estimativa inicial ; assim sendo, espera-se que a sequência se aproxime do valor real de . Calculam-se alguns termos dessa sequência, até ser menor que uma precisão desejada. Nesse momento usa-se como valor inicial para o seguinte intervalo e o processo repete-se iterativamente em todo o intervalo de .
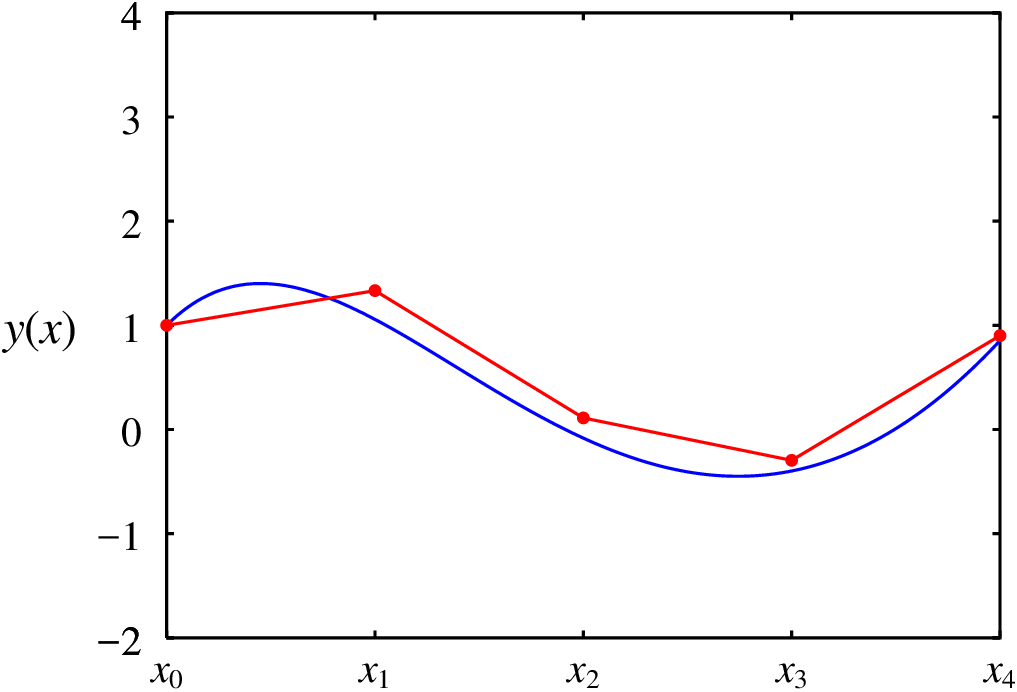
No caso do mesmo problema resolvido em (%i15), com e usando precisão de 0.0001 para , o método pode ser implementado assim:
(%i17) f(x,y) := (x-1)*(x-3)-y$
(%i18) p: [[0.0, 1.0]]$
(%i19) for i thru 4 do (
[xi,yi]: last(p),
y1: yi,
y2: yi + (f(xi,yi)+f(xi+1,y1))/2,
while abs(y1-y2) > 0.0001 do (
y1: y2, y2: yi + (f(xi,yi)+f(xi+1,y1))/2),
p: endcons ([xi+1, y2], p)
)$
(%i20) p;
(%o20) [[0.0, 1.0], [1.0, 1.33331298828125], [2.0, 0.11112297885119915],
[3.0, - 0.2962674737252655], [4.0, 0.9012259028472571]]
Definiu-se novamente a função , acrescentando o comando float, para evitar obter fracções com numeradores e denominadores muito grandes; nos exemplos anteriores foram feitos menos cálculos e, por isso, não produziram frações com números grandes. O resultado (ver figura 3.6) mostra que a solução obtida está mais próxima da verdadeira solução do que as aproximações apresentadas nas figuras 3.3 e 3.5.
A pesar de se ter usado uma precisão de 0.0001, não se pode garantir que a solução obtida esteja dentro dessa precisão em relação á solução real, já que a equação 3.13 é apenas uma aproximação e não o valor médio real da derivada. Para melhorar essa aproximação, em vez de se obter a média do declive em dois pontos será necessário fazer uma média em vários pontos do intervalo em questão, com diferentes pesos que podem ser definidos de forma a minimizar o erro. Existem muitos métodos diferentes que usam esse esquema; o mais popular é o que será descrito na seguinte secção.
3.2.3. Método de Runge-Kutta de quarta ordem
Neste método o valor médio do declive obtém-se a partir da média dos declives em 4 pontos diferentes, com pesos diferentes (figura 3.7).
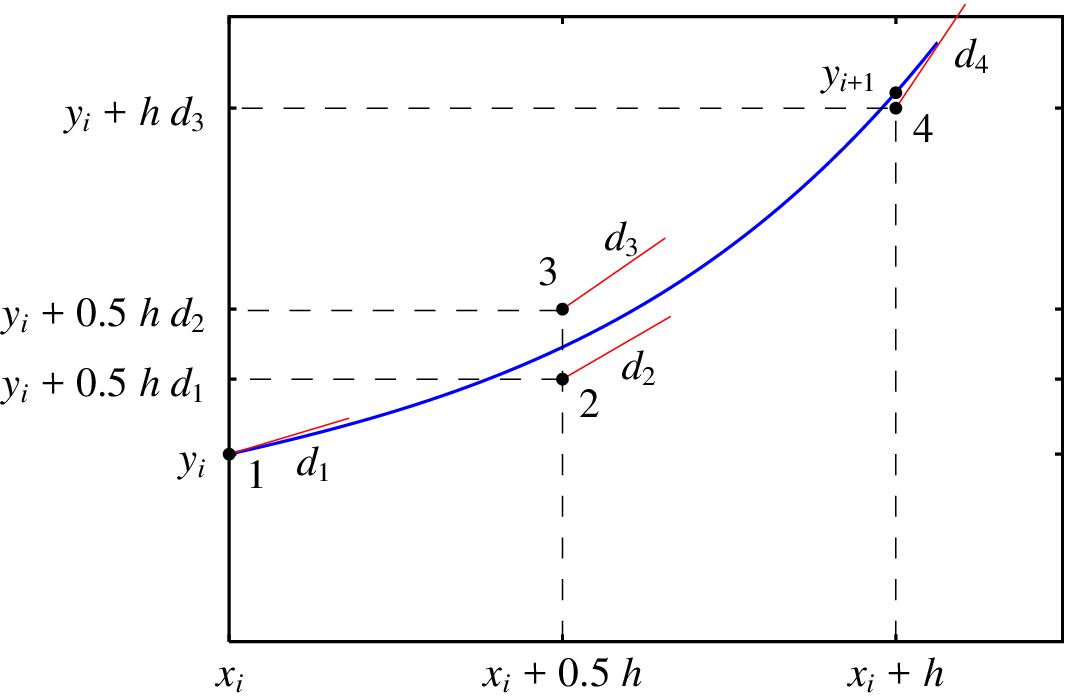
Começa-se por calcular o declive no ponto inicial do intervalo, tal como no método de Euler:
a seguir, realiza-se um deslocamento na direção desse declive, avançando-se uma distância no eixo das abcissas, até um ponto 2 (ver figura 3.7). Nesse ponto 2, calcula-se um segundo valor do declive
Esse novo valor do declive é usado novamente, para realizar outro deslocamento a partir do ponto inicial, avançando na direção do eixo das abcissas, até um outro ponto 3, onde é calculado um terceiro valor do declive
seguindo a direção desse declive , realiza-se um terceiro deslocamento, a partir do ponto inicial, desta vez avançando uma distância no sentido do eixo das abcissas, para chegar até um ponto 4, onde se calcula um quarto valor do declive
Pode mostrar-se que para minimizar o erro cometido, o valor médio do declive deve ser aproximado pela seguinte combinação linear dos quatro declives calculados:
no exemplo da figura 3.7, esse valor médio da derivada desloca o ponto inicial até o ponto 4, que está bastante próximo da solução exata da equação.
Para aplicar este método à mesma equação considerada nas secções anteriores, com valor inicial = 1 e com 5 pontos no intervalo , inicia-se a lista de pontos (a função que define o declive em cada ponto é a função que já está definida)
(%i21) p: [[0.0, 1.0]]$
(%i22) h: 1.0$
Neste caso foi dado explicitamente o valor do comprimento dos intervalos, para que as expressões seguintes sejam mais claras.
A seguir realizam-se as 4 iterações necessárias para chegar até o ponto . Em cada iteração calculam-se os quatro declives , , e e a média com os pesos dados na equação 3.18.
(%i23) for i thru 4 do (
[xi,yi]: last(p),
d1: f(xi, yi),
d2: f(xi+h/2, yi+(h/2)*d1),
d3: f(xi+h/2, yi+(h/2)*d2),
d4: f(xi+h, yi+h*d3),
p: endcons ([xi+h, yi + h*(d1+2*d2+2*d3+d4)/6], p)
)$
(%i24) p;
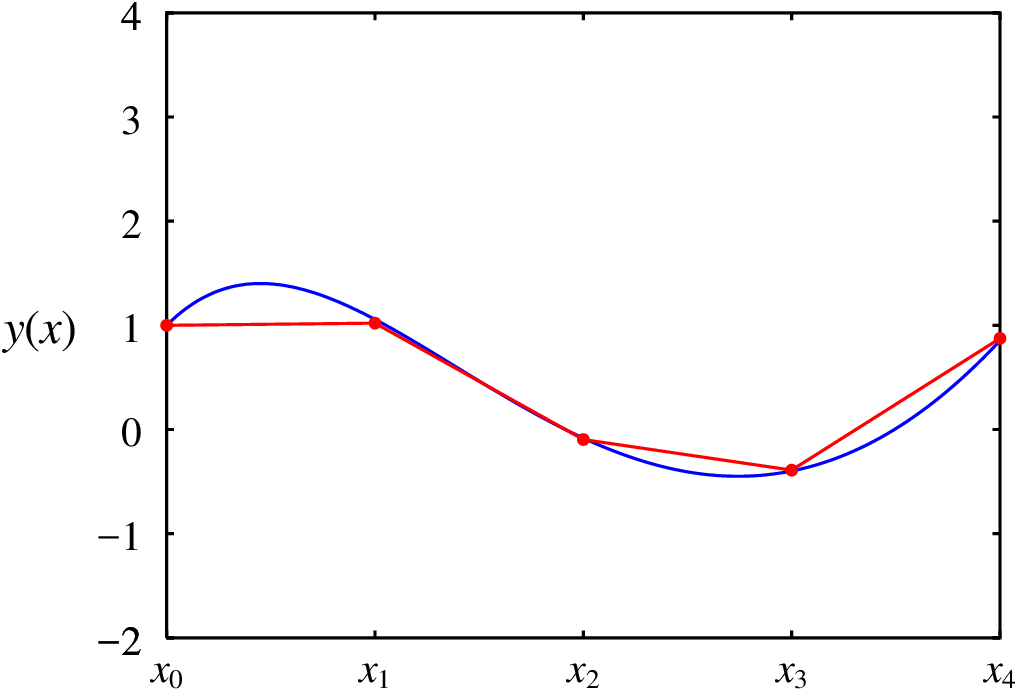
(%o24) [[0.0, 1.0], [1.0, 1.0208333333333333], [2.0, -0.09635416666666652],
[3.0, -0.3902994791666666], [4.0, 0.8744710286458335]]
A figura 3.8 mostra a sequência de pontos obtida, juntamente com a solução exata (curva contínua na figura). O resultado é bastante bom, a pesar do valor tão elevado que foi usado para os incrementos da variável . No caso da equação diferencial resolvida neste exemplo, existem métodos analíticos que permitem encontrar a expressão para a curva contínua que foi apresentada na figura; nos casos em que não é possível encontrar a solução analítica, o método de Runge-Kutta de quarta ordem é uma boa opção para encontrar uma boa aproximação numérica.
Já existe uma função rk predefinida no Maxima que executa o método de Runge-Kutta de quarta ordem. No exemplo acima, bastava indicar a expressão de , o nome que identifica a variável dependente, o seu valor inicial e o intervalo em que se quer obter a solução, incluindo o valor dos incrementos . Assim sendo, a mesma lista obtida com os comandos (%i17), (%i21), (%i22) e (%i23) podia ser obtida com um único comando:
(%i25) rk ((x-1)*(x-3)-y, y, 1, [x, 0, 4, 1]);
(%o25) [[0.0, 1.0], [1.0, 1.020833333333333], [2.0, -0.09635416666666652],
[3.0, -0.3902994791666666], [4.0, 0.8744710286458335]]